
概要
技術トラブルは必ず起こるものとして備えよ
ITシステム開発に限らず、あらゆるプロジェクトにおいて、技術的な問題や予期せぬ障害の発生は、残念ながら避けられない現実です。
「開発中のシステムが想定通りに動作しません」「連携する外部システムに障害が発生しました」「導入した新技術に未知のバグがありました」「データ移行中に問題が発生し、サービスが停止しました」…。
これらはIT分野の例ですが、製造業における設備の故障、建設業における設計上の問題など、様々なプロジェクトで同様の事態が発生し得ます。これらの技術トラブルは、プロジェクトの進捗を大幅に遅らせ、コストを増大させ、時にはプロジェクトの目標達成そのものを危うくします。
事前にどれだけ綿密な計画やテストを行っても、「想定外」の事態は起こり得るものです。
本記事では、一般的なプロジェクトにおいて技術的な問題や予期せぬ障害がなぜ発生するのか、その要因を分析するとともに、Vision Consultingが提唱する、トラブル発生時の迅速な対応と、将来の発生を抑制・影響を最小化するためのプロアクティブなアプローチについて解説いたします。
なぜ技術トラブルは「予期せず」やってくるのか?
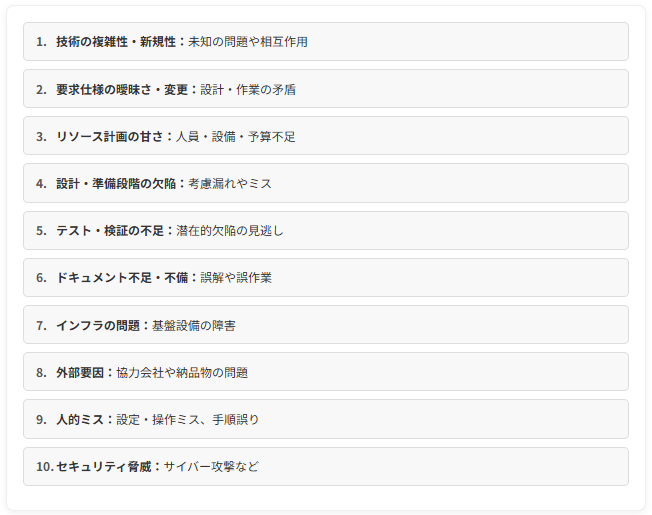
一般的なプロジェクトで技術的な問題や障害が発生する背景には、様々な要因が潜んでいます。
・技術の複雑性、新規性: プロジェクトで扱う技術や手法が新しい、または複雑な要素を多く含む場合、未知の問題や予見しきれない相互作用が発生する可能性が高まります。
・要求仕様の曖昧さ、変更: プロジェクトの目的や成果物に対する仕様が不明確だったり、プロジェクト途中で頻繁に変更されたりすることで、設計や作業に矛盾が生じ、問題を引き起こすことがあります。
・リソース計画の甘さ: 将来の負荷増大や必要となるリソース(人員、設備、予算など)の見積もりが不十分で、プロジェクト進行中に問題や障害が発生することがあります。
・設計、準備段階の欠陥: 設計段階での考慮漏れや、準備段階でのミスが、後の工程で問題として顕在化いたします。
・テスト、検証の不足: テストケースの網羅性不足、テスト環境と実際の運用環境の差異、異常系のテスト不足などにより、潜在的な欠陥が見逃されることがあります。
・ドキュメント不足、不備: 設計書や手順書などのドキュメントが不十分または不正確で、誤った理解や作業に繋がることがあります。
・インフラストラクチャの問題: プロジェクトの基盤となる設備、システム、ツールなどに予期せぬ障害が発生することがあります。
・外部要因(協力会社、納品物など): 連携している協力会社や、利用している外部の納品物、サービスなどに障害や仕様変更が発生し、影響を受けることがあります。
・人的ミス: 設定ミス、操作ミス、手順の誤りなど、人間の不注意やスキル不足に起因する問題も依然として多く存在いたします。
・セキュリティ上の脅威: 情報システムを扱うプロジェクトでは、サイバー攻撃や不正アクセスなど、外部からの悪意ある攻撃によってシステム障害が発生することもあります。
技術トラブルがプロジェクトを蝕む深刻な悪影響
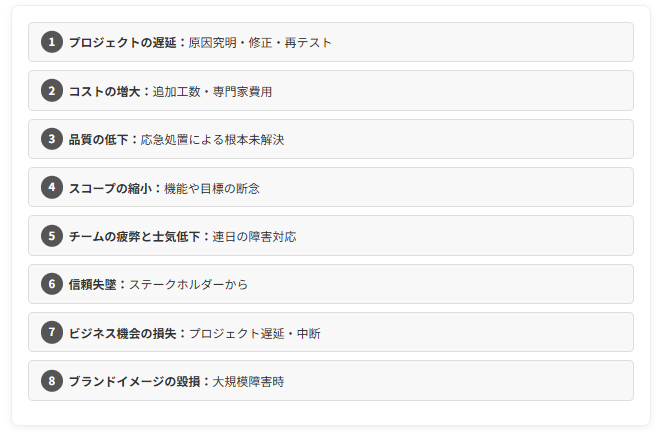
技術的な問題や予期せぬ障害は、一度発生すると連鎖的に悪影響を及ぼし、プロジェクトを危機に陥れます。
・プロジェクトの遅延: 問題の原因究明、修正、再テストに時間がかかり、スケジュールが大幅に遅延いたします。
・コストの増大: 追加の調査・修正工数、専門家への依頼費用、場合によっては設備や資材の再調達などで、予算を超過いたします。
・品質の低下: 応急処置的な対応により、根本的な解決がなされなかったり、新たな問題を生み出したりして、成果物の品質が低下することがあります。
・スコープの縮小: 問題解決のために、当初予定していた機能や目標の一部を断念せざるを得なくなることがあります。
・チームの疲弊と士気低下: 連日の障害対応や原因究明作業に追われ、メンバーが心身ともに疲弊し、モチベーションが低下いたします。
・ステークホルダーからの信頼失墜: 成果物の納品遅延や品質問題などにより、顧客やスポンサーからの信頼を大きく損なうことがあります。
・ビジネス機会の損失: プロジェクトの遅れや中断により、ビジネス上の機会を逃してしまうことがあります。
・ブランドイメージの毀損: 大規模な障害や問題が発生した場合、企業のブランドイメージに深刻なダメージを与える可能性があります。
Vision Consulting流「レジリエンス強化」戦略
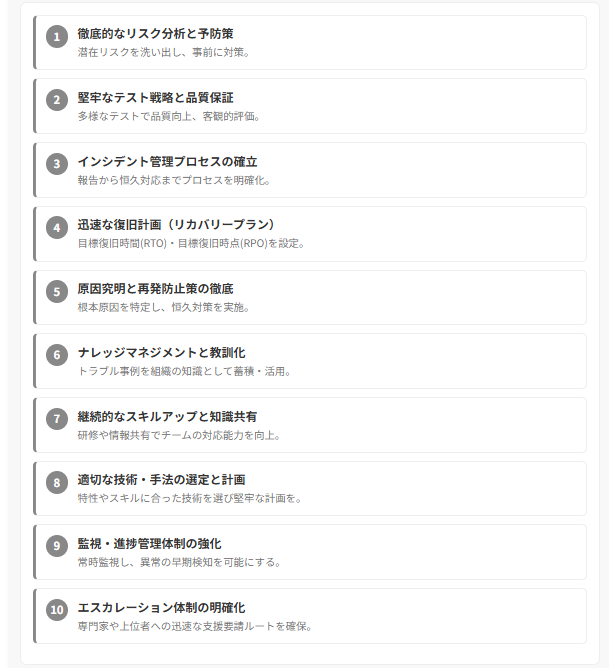
Vision Consultingは、技術トラブルの発生をゼロにすることは不可能であるという前提に立ち、その影響を最小限に抑え、迅速に回復するための「レジリエンス(回復力・しなやかさ)」を高めるアプローチを重視いたします。
1. 徹底的なリスク分析と予防策: プロジェクトの特性や技術要素を分析し、潜在的な問題点や障害発生のリスクを洗い出し、可能な限りの予防策(設計の見直し、代替案の準備、品質管理の強化など)を事前に講じます。
2. 堅牢なテスト戦略と品質保証: 多様なテスト手法や検証プロセスを組み合わせ、成果物の品質を高めます。独立した品質保証部門による客観的な評価も重要です。
3. インシデント管理プロセスの確立: 問題発生時の報告ルート、一次切り分け、原因調査、暫定対応、恒久対応、関係者への連絡といった一連のインシデント管理プロセスを明確に定義し、訓練しておきます。
4. 迅速な復旧計画(リカバリープラン): プロジェクトにおいて重大な障害が発生した場合に、どの程度の時間で、どのレベルまで復旧させるかという目標(RTO: Recovery Time Objective, RPO: Recovery Point Objective など、状況に応じて設定)を定め、具体的な復旧手順と体制を準備しておきます。
5. エスカレーション体制の明確化: 技術的に解決困難な問題が発生した場合に、専門家チームや上位者、外部ベンダーなどに迅速に支援を要請できるエスカレーションルートを確保しておきます。
6. 原因究明と再発防止策の徹底: 問題が発生した場合、場当たり的な対応だけでなく、根本原因を特定し、恒久的な対策と再発防止策を確実に実施します。
7. ナレッジマネジメントと教訓化: 発生した技術トラブルの原因、対応策、結果を記録・共有し、組織全体の知識・教訓として蓄積・活用します。
8. 継続的なスキルアップと知識共有: チームメンバーのスキル向上のための研修や情報共有を継続的に行い、技術的な課題への対応能力を高めます。
9. 適切な技術、手法の選定と計画: プロジェクトの特性やチームのスキルレベルに合った技術や手法を選定し、変更に強く堅牢な計画を心がけます。
10. 監視、進捗管理体制の強化: プロジェクトの進捗状況、課題、リスクなどを常時監視し、異常の早期検知を可能にする体制を構築します。
事例紹介/筆者経験
あるECサイト構築プロジェクトで、リリース直後に予期せぬアクセス集中により、システムが応答不能になる障害が発生しました。
幸い、プロジェクトでは事前に負荷テストを実施し、アクセス急増時のリスクを認識していたため、サーバー増強手順や緊急連絡体制を含むリカバリープランを準備していました。
障害発生後、チームはプランに基づき迅速に対応いたしました。関係各所への連絡と並行して、数時間以内にサーバーを増強し、サービスを復旧させることができました。
その後、アクセスログを詳細に分析し、ボトルネックとなっていた箇所を特定・改修することで、恒久的な対策を実施いたしました。
この事例は、予期せぬ障害は起こり得るという前提のもと、事前のリスク分析と準備(リカバリープラン)がいかに重要かを示しています。
障害対応力は組織の競争力
デジタル化が進む現代において、システムの安定稼働はビジネスの生命線です。
一般的なプロジェクトにおいても、予期せぬ問題への対応力は、単にプロジェクトを守るだけでなく、顧客からの信頼を獲得し、事業継続性を確保するための重要な経営課題となっています。
インシデント対応プロセスを標準化し、迅速な復旧と効果的な再発防止を実現できる組織は、変化の激しい市場においても高い競争力を維持することができます。
また、障害対応の経験を通じて得られた知見は、より堅牢で信頼性の高いプロセスやシステム設計へと繋がり、組織全体の遂行能力を底上げいたします。
検討手順
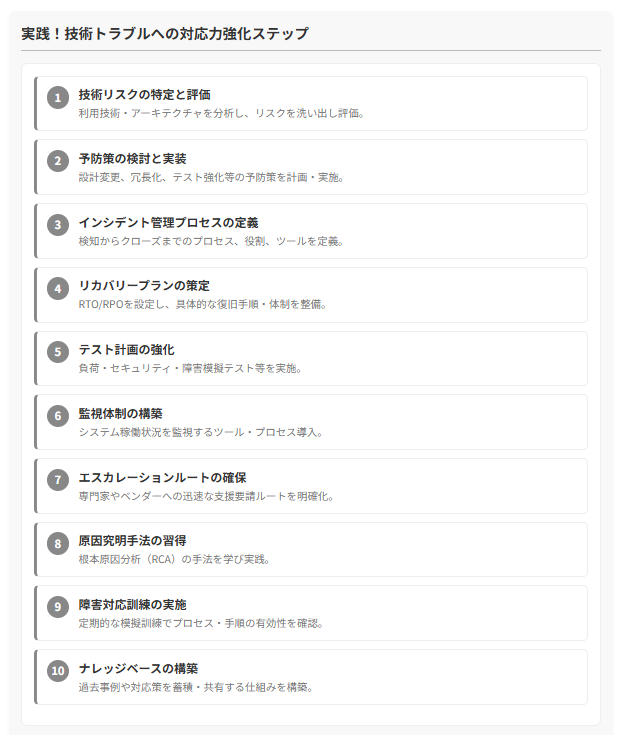
プロジェクトにおける技術トラブルへの対応力を強化するための具体的なステップは以下の通りです。
1. 技術リスクの特定と評価: プロジェクトで利用する技術要素、アーキテクチャ、連携システムなどを分析し、潜在的なリスクを洗い出し、発生可能性と影響度を評価します。
2. 予防策の検討と実装: 特定されたリスクに対して、設計変更、冗長化、テスト強化などの予防策を検討し、計画に組み込みます。
3. インシデント管理プロセスの定義: 問題検知から報告、調査、対応、クローズまでのプロセス、役割、利用ツールを定義します。
4. リカバリープランの策定: RTO/RPOを設定し、具体的な復旧手順、体制、連絡網などを定めます。
5. テスト計画の強化: 負荷テスト、セキュリティテスト、障害模擬テストなど、潜在的な問題を検出するためのテストを計画・実施します。
6. 監視体制の構築: システムの稼働状況を監視するためのツールやプロセスを導入します。
7. エスカレーションルートの確保: 内部の専門家や外部ベンダーへのエスカレーション手順を明確にします。
8. 原因究明手法の習得: 根本原因分析(RCA)の手法を学び、実践します。
9. 障害対応訓練の実施: 定期的に障害発生を想定した訓練を行い、プロセスや手順の有効性を確認します。
10. ナレッジベースの構築: 過去の障害事例や対応策を蓄積・共有するための仕組みを構築します。
おわりに
技術的な問題や予期せぬ障害は、プロジェクトにとって避けがたい試練です。
しかし、その発生を前提とし、事前にリスクを分析し、堅牢な予防策と迅速な復旧計画を準備しておくことで、影響を最小限に抑え、プロジェクトを軌道に戻すことが可能です。
Vision Consultingは、技術リスクアセスメントから、インシデント管理プロセス構築、リカバリープラン策定、そして障害対応訓練まで、貴社のプロジェクトが技術トラブルを乗り越え、成功するための「レジリエンス」強化を支援いたします。
「技術的な不安要素が多いです」「過去に大きな障害で苦労しました」「万が一の備えが十分か心配です」と感じているなら、ぜひVision Consultingにご相談ください。
想定外の事態にも動じない、しなやかで強いプロジェクト運営体制を共に築き上げましょう。
➨コンサルティングのご相談はこちらから
補足情報
関連サービス:プロジェクトマネジメント、PMO構築・運営支援、リスクマネジメント、ITサービスマネジメント(ITSM)、インシデント管理プロセス構築、事業継続計画(BCP)策定支援、システムテスト・品質保証
キーワード:技術的問題、システム障害、インシデント管理、障害対応、リカバリープラン、RTO/RPO、再発防止、根本原因分析(RCA)、リスク管理、レジリエンス、ITSM、ITIL、テスト自動化、システム監視
